Purpose of the Database
The idea for this database project originated during my Database Administration course at the Federal Institute of Rio Grande do Sul. My objective was to apply the key concepts learned in the course to organize and manage my personal reading data using best practices.
By building this database, I aimed to gain hands-on experience with database design, data transformation, and management, while creating a tool to track and analyze my reading habits.
Tools and Technologies
1. Data Acquisition (Extract and Transform)
I began registering my readings in 2019, when I became an avid reader and started using the Goodreads app.
Goodreads functions as a social network for readers, offering features like book searches, virtual shelves, reading progress updates, and social interactions with other users. It also allows users to export their reading data in a tabular format (.csv file), which includes information such as book titles, authors, number of pages, end dates, and personal ratings.
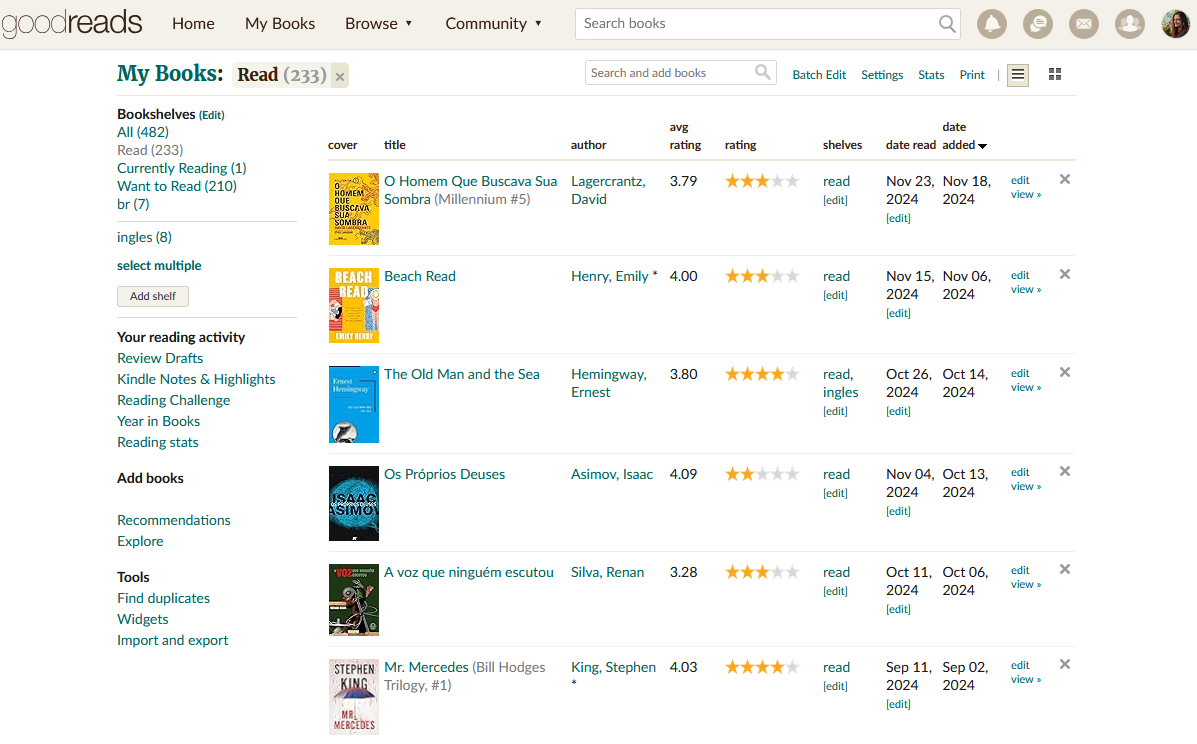

However, the exported data lacks key information available on the platform, such as the start date of each book and its genre. To fill this gap, I also exported my reading database from Notion, which I had been using to track additional details about my readings.
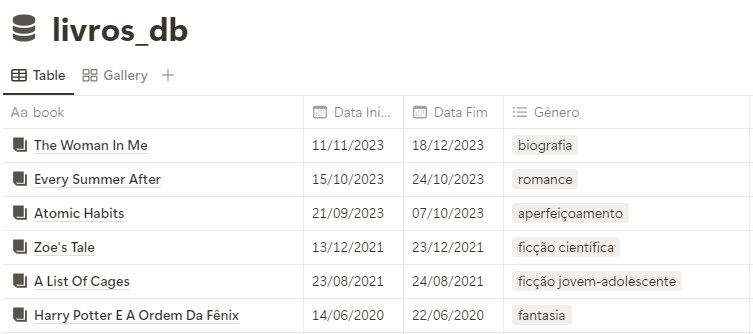
After exporting the data, I performed a data transformation step using Python. This step involved cleaning the dataset, removing unnecessary columns (e.g., ISBN, average rating, publisher, binding), and combining information from Goodreads and Notion into a final, cohesive table.
Challenges and Solutions:
- Missing data: Start dates and genres were added manually from Notion exports.
- Data cleaning: Python scripts were used to ensure the data was well-structured and aligned for import into the database.
2. Database Structure
a. Conceptual Model
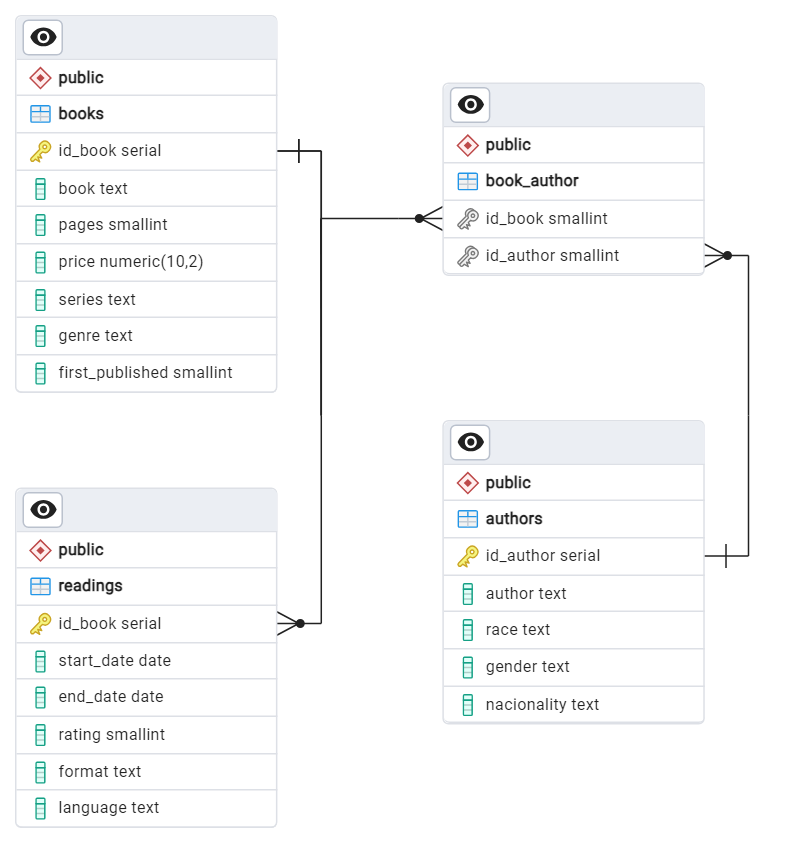
The structure of my database was designed based on the principles of normalization learned in my course. I decomposed the all-in-one table into multiple smaller, related tables to minimize redundancy and maintain data integrity. The final design includes four tables:
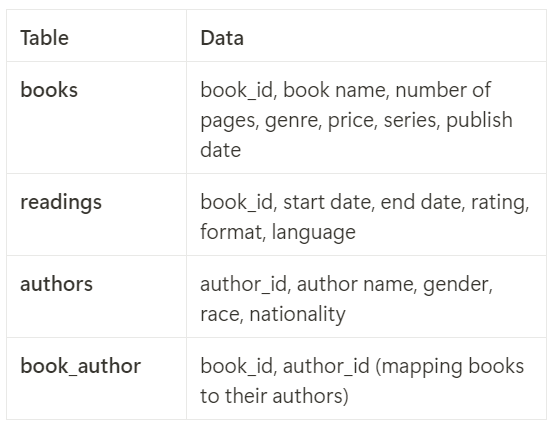
- Books Table: Stores information intrinsic to the book, such as its title, genre, and publication details.
- Readings Table: Captures personal experiences with the books, such as start and end dates, ratings, and formats, allowing for multiple readings of the same book.
- Authors Table: Includes demographic data about authors for analytical purposes.
- Book_Author Table: Resolves the many-to-many relationship between books and authors, accommodating cases where a book has multiple authors or an author has written multiple books.
The relationships between these tables are illustrated in the conceptual model below:
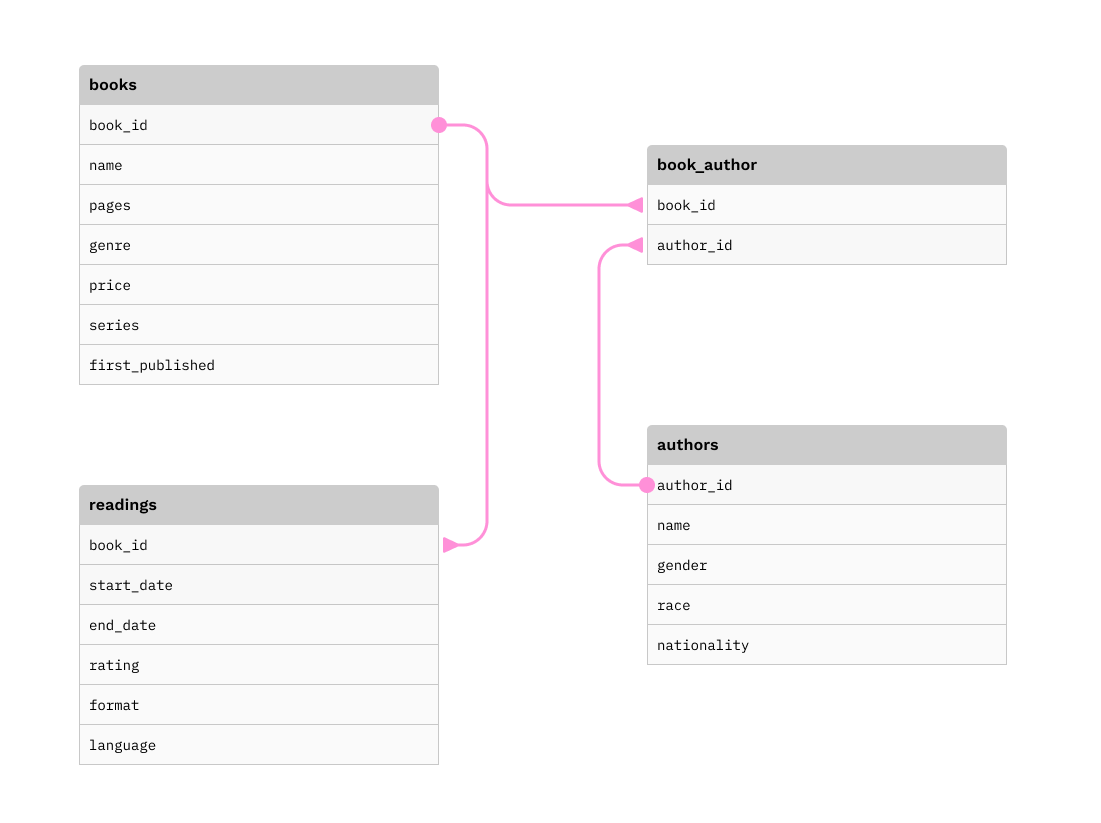
b. Database Management System (DBMS)
I selected PostgreSQL as the database management system (DBMS) for this project due to its reliability, open-source nature, and extensive community support. I used pgAdmin as the graphical interface to manage the database.
To create the tables and define their attributes, I used both SQL scripts and pgAdmin's GUI. While SQL scripting allowed me to practice and deepen my understanding of the language, the GUI provided an intuitive method for defining relationships and constraints, which was especially helpful for a first-time database project.
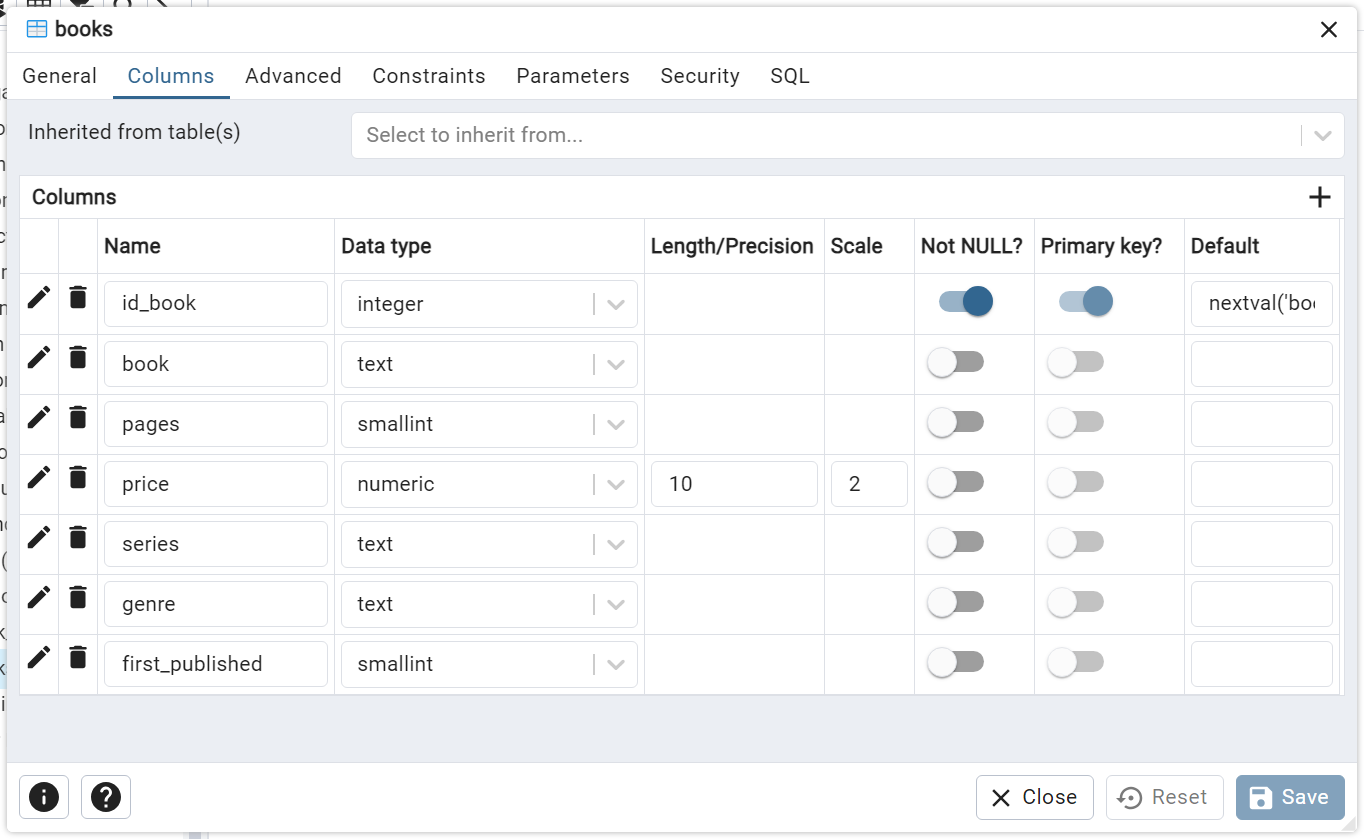
Sample SQL script used to create the "books" table:
id_book INTEGER PRIMARY KEY,
book TEXT NOT NULL,
pages SMALLINT,
price NUMERIC(10, 2),
series TEXT,
genre TEXT,
first_published SMALLINT);
The database structure was further visualized through an Entity-Relationship Diagram (ERD), created using pgAdmin tools:
3. Data Import (Load)
Once the database structure was finalized, I imported the prepared data from .csv files into the corresponding tables. I used pgAdmin's import tool to handle this step efficiently. These .csv files also serve as templates for future data imports. For ongoing updates, I plan to manually add new rows using the pgAdmin interface.
Final Considerations, Lessons Learned, and Future Plans
The primary goal of this project was to learn database administration while organizing data I already managed using other tools. By tackling various challenges in each step—data extraction, transformation, modeling, and loading—I strengthened my understanding of database principles and best practices.
Key Lessons:
- Designing normalized database structures improves scalability and reduces redundancy.
- Python is an excellent tool for data cleaning and transformation tasks prior to database imports.
- PostgreSQL and pgAdmin, both open-source tools, offer robust features for managing and visualizing relational databases.
Future Plans:
- Add a new table to track progress on book series (e.g., percentage completed).
- Develop an automation script to directly extract and import data from Goodreads into the database using Goodreads API.
- Use the database as a data source for a Power BI dashboard, enabling dynamic analysis of reading trends and habits.